An HPF Implementation of the Multigrid Method and Effectiveness of Compiler
Optimizations
Hiroshi Ohta, Systems Development Laboratory, Hitachi, Ltd.,
ohta@sdl.hitachi.co.jp
Yasunori Nishitani, Kiyoshi Negishi, Eiji Nunohiro, Software
Development Division, Hitachi, Ltd.
Multigrid method is a widely-used Poisson solver algorithm and is included
in the NAS Parallel Benchmarks (NPB) as the benchmark MG [1].
The method uses several grids of different coarseness and requires projection
and interpolation between these grids. These
characteristics introduce complex array subscripts. For instance, code
fragment taken from NPB/MG interpolation routine looks like:
u(2*i1-1,2*i2-1,2*i3) = z(i1,i2,i3+1)+z(i1,i2,i3)+...
Since many HPF compilers cannot generate efficient code for such complex
subscripts, previous HPF implementations of MG resulted in poor performance
[2]. In this study, we present an efficient HPF implementation
of MG and compiler optimizations needed to achieve good performance.
We used the following techniques for the HPF implementation.
-
We distribute among processors only the four finest grids. The remaining
coarser grids are packed into a 1D work array and are replicated onto all
processors. This technique allows portability in changing the problem size.
Although the computation of the coarser grids is replicated, the overall
performance is not very much affected because the amount of computation
is much smaller than that of the finer grids.
-
We declare a template to which we align the grids of different coarseness
with different strides, then distribute the template in 2D. The HPF directives
in the main routine are shown below:
!HPF$ template maxgrid(nm3*8,nm3*8,nm3*8)
!HPF$ align (i,j,k) with maxgrid(i,j,k) :: u0
!HPF$ align (i,j,k) with maxgrid(2*i-1,2*j-1,2*k-1) :: u1
!HPF$ align (i,j,k) with maxgrid(4*i-3,4*j-3,4*k-3) :: u2
!HPF$ align (i,j,k) with maxgrid(8*i-7,8*j-7,8*k-7) :: u3
!HPF$ distribute maxgrid(*,block,block)
As the kernel subroutines are common to these grids, the alignment stride
is not constant in these subroutines. So we pass the alignment stride as
an argument to the subroutines and use it in the ALIGN directives therein.
We declare shadow edges for the distributed grids to allow shadow communication.
Given such code, the compiler must generate efficient communication. Our
compiler generates communication based on a remapping concept [3].
It utilizes remapping libraries for general cases, but uses more efficient
communication libraries for specific patterns that frequently appear in
practical applications. It performs the following optimizations for specific
cases:
-
(1) Replaces a remapping with a shadow communication for a nearest-neighbor
reference.
-
(2) Merges multiple shadow communications.
-
(3) Replaces a remapping with a one-to-one communication for a boundary
value exchange.
We compiled our HPF implementation of MG with our prototype compiler and
executed it in Hitachi SR2201, a distributed-memory parallel machine. Figure
1 shows the execution time with various optimization options shown
in Table 1. We also show, for comparison, the timings
for the hand-parallelized MPI code provided by NASA (NPB2.3-beta).
We could not run 'remap' in 16 processors due to large memory requirement.
We could run 'remap' in 32 and 64 processors but the execution time is
significantly long. As we perform more optimizations, the execution time
gets shorter and closer to the 'MPI' time. With all optimizations, the
execution time is only 18% longer compared to MPI, in the case of 16 processors,
class B. We conclude that sufficiently good performance is achieved with
our HPF implementation and compiler optimizations.
| label |
optimizations |
remap
shadow
merge
1to1
MPI |
no optimization
(1)
(1)+(2)
(1)+(2)+(3)
hand-parallelized MPI (NPB2.3-beta) |
Table 1. Optimization options.
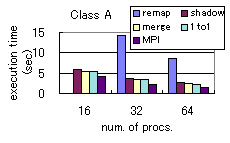
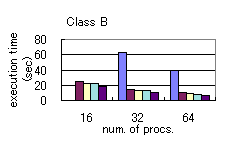 Figure 1. Execution time of MG.
Figure 1. Execution time of MG.
References
-
NASA, The NAS Parallel Benchmarks, http://www.nas.nasa.gov/Software/NPB/
-
M. Frumkin, H. Jin and J. Yan, "Implementation of NAS
Parallel Benchmarks in High Performance Fortran," IPPS'99
-
T. Kamachi, K. Kusano, K. Suehiro, Y. Seo, M. Tamura,
and S. Sakon, "Generating Realignment-Based Communication for HPF Programs,"
IPPS '96, pp.364-371.