第1章
HPF入門
一般的に、分散メモリ型の並列コンピュータシステム
上でのプログラム開発において、
まず考慮しなければならないのは以下のような事柄です。
- データの並列化 (データマッピング)
-
各データをどのプロセッサのメモリ上に割り付けるかを
決定する必要があります。これをデータマッピングと言います。
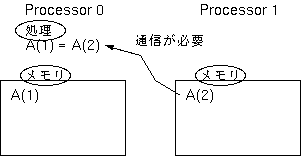
リモートプロセッサのメモリ上に割り付けられたデータのアクセスは、
ローカルなメモリ上に割り付けられたデータのアクセス
に比べて大きなオーバヘッドが伴うので、
一つの処理に関連するデータは、出来るだけ同じプロセッサのメモリ上に
割り付ける必要があります。
- 処理の並列化 (計算マッピング)
-
演算や代入、分岐といった処理をどのプロセッサが実行するのか
を決定する必要があります。これを計算マッピングと言います。
この際、リモートプロセッサのメモリ上にあるデータには直接アクセスする
ことができませんから、もし、ある処理を行うプロセッサとその処理に必要な
データが割り付けられているプロセッサが異なる場合、必要なデータに対す
る
通信
も必要になります。
一般に、N台のプロセッサを利用して、N倍のSpeed Upを実現するためには、
各プロセッサに割り当てられた処理が同時並行的に行えると共に、
各プロセッサの処理量が均等であることが必要となります。
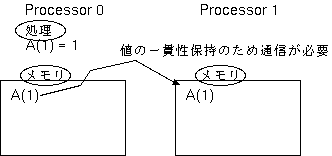
さらに、同一のデータが複数のプロセッサのメモリ上に複製されて割り付けられていて、
そのうち1つのプロセッサに割り当てられた処理でそのデータが定義された場合には、
値の一貫性を保つために、定義された値を
他のプロセッサのメモリ上の複製にも反映させる必要がありますし、
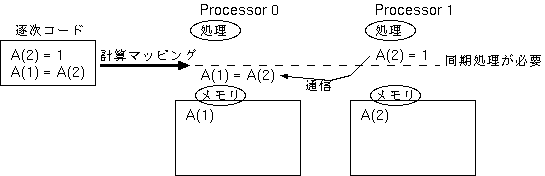
あるデータが定義されてから引用されるような場合、
定義処理と引用処理が別のプロセッサ上で行われるならば、
正しい値を参照することができるように、プロセッサ間での同期処理も
必要になってきます。
例えば、MPIを用いて並列プログラムを記述する場合のように、
これら全てのことを考慮にいれた上で、効率の良い
並列プログラムを作成することは、大変に手間のかかる作業です。
それに対して、HPFの基本的なコンセプトは、プログラマには、
データマッピングだけを考えてもらい、HPFコンパイラは、それに基づいて、
計算マッピングを行い、その際に必要となるリモートアクセス制御、
複製データの値の一貫性保持、及びプロセッサ間の同期、といった処理
も全て自動的に行ってしてしまおう、というものです。
そのため、プログラマは、データがローカルメモリ上
にあるか、リモートプロセッサのメモリ上にあるか、といった
区別をせずに、
直接全てのデータを参照できるかのようなプログラミングが可能になります。
このようなプログラミングモデルを、HPFでは
グローバルモデル
といいます。
HPFコンパイラは、主として、並列化可能なループの各繰り返しを各プロセッサに
割り振ることで並列化を行いますが、その際、プログラマが指定した
データの各プロセッサ上へのマッピングに基づいて、
データアクセスができるだけローカルになるように、
計算マッピングを行います。
したがって、HPFプログラミングにおいて、プログラマが行う主要な作業は、
プログラム中の並列化可能なループでアクセスされる
配列データの次元を、適切な方法で各プロセッサ上にマップすることです。
1.2.1
例1
最初に、以下のFortranプログラムをみてみましょう。
二つのベクトルB、Cの和をAに求めるだけのプログラムですが、
このままでは、
HPFコンパイラは、
全く並列化を行いません。
INTEGER A(10),B(10),C(10)
DATA B /10*1/
DATA C /10*1/
DO I=1,10
A(I) = C(I)+B(I)
ENDDO
WRITE(*,*)A
END
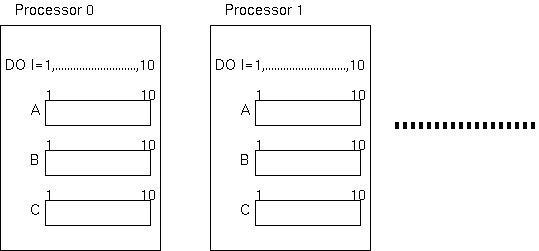
実際、
HPFコンパイラは、
なにもマッピングが指定されていない配列は、
全ての抽象プロセッサのそれぞれに、配列全体のコピーを割り付けます。
ここで、
抽象プロセッサ
とは、HPFでの処理単位を意味しており、
HPFのデータマッピングは、抽象プロセッサ上への配列データの
割り付け方を決めること、HPFの計算マッピングは、抽象プロセッサ上への
処理の割り当てを決めることを意味しています。
HPFコンパイラは、
できる限り、各抽象プロセッサ上に割り付けられているローカルな配列データ
だけをアクセスする様に
計算マッピングを行いますから、
結局
マッピング指定なしの場合
の図のように
全抽象プロセッサが、それぞれDO Iのループの全範囲を実行することになり、
何台で実行しても、1台で実行する以上の性能は出ないことになります。
このプログラムをHPFによって、2台の抽象プロセッサ上で並列化することを考えてみましょう。
10要素の各配列A、B、Cを半分ずつに分けて、前半分の計算を最初の
抽象プロセッサ上で、
後半分の計算を2番目の抽象プロセッサ上で実行させれば、
1つの抽象プロセッサ上での実行と比べて
2倍近い性能が得られるのではないかと期待できます。
このような場合、HPFプログラミングの基本的な作業は、
各配列を各抽象プロセッサ上にどのように分けるかを指定することです。
すなわち、以下の2つの作業を行うことになります。
- 2つの抽象プロセッサ上で実行するので、PROCESSORS指示文で、
2要素の抽象プロセッサからなるプロセッサ構成を宣言する。
- DISTRIBUTE指示文によって、配列データの抽象プロセッサ
へのマッピング方法を指定する。
この場合、各配列の前半分の要素と後半分の要素を
各抽象プロセッサ上に均等にマップしたいので、
配列要素の連続した塊を均等に分散するための
分散形式であるBLOCK分散を選択する。
すると、最終的なHPFプログラムは元のプログラムに、
2行のHPF指示文を追加した以下のようなものになります。
INTEGER A(10),B(10),C(10)
DATA B /10*1/
DATA C /10*1/
!HPF$ PROCESSORS P(2) ! プロセッサ構成の宣言
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: A,B,C ! 分散の指定
DO I=1,10
A(I) = C(I)+B(I)
ENDDO
WRITE(*,*)A
END
例えば
HPF/ESの場合、
HPFソースプログラムを
以下のような
SPMD (Single Program Multiple Data)モデル
の
中間ソース
に翻訳します。
SPMDモデルでは、
各抽象プロセッサは、基本的に同じコードを実行しますが、
それぞれ異なる範囲のデータに対して、処理を行うことになります。
(HPFでは、SPMDモデルのことを、
ローカルモデル
と呼びます。)
LB = MYID * 5
DO I = LB + 1, LB + 5
A(I) = C(I) + B(I)
ENDDO
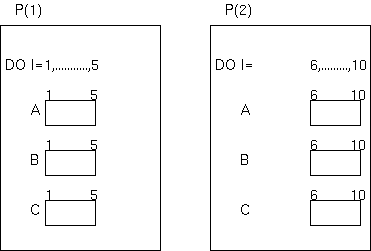
上記の中間ソースでは、変数MYIDの値が、抽象プロセッサP(1)では0
、抽象プロセッサP(2)では1、と異なる値が設定されているため、
結局各抽象プロセッサは、ループの以下のような範囲を実行することになります。
! Processor P(1)
DO I = 1, 5
A(I) = C(I) + B(I)
ENDDO
! Processor P(2)
DO I = 6, 10
A(I) = C(I) + B(I)
ENDDO
プログラムの開発段階など、抽象プロセッサ数を固定でなく、
実行時に必要に応じて変更したい、という場合もあるでしょう。
このような場合、HPF仕様で定義されている、
NUMBER_OF_PROCESSORS()
という
組込み関数を利用して、利用可能な抽象プロセッサ数を
実行時に取得することができます。
上記のPROCESSORS指示文を以下のように変更すれば、
抽象プロセッサ数をプログラムの実行開始時に指定することができます。
INTEGER A(10),B(10),C(10)
DATA B /10*1/
DATA C /10*1/
!HPF$ PROCESSORS P(NUMBER_OF_PROCESSORS()) ! プロセッサ構成の宣言
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: A,B,C
DO I=1,10
A(I) = C(I)+B(I)
ENDDO
WRITE(*,*)A
END
この例のように、全ての配列データを一つの次元だけでマップする場合には、
PROCESSORS指示文と、DISTRIBUTE指示文中の
ONTO節
を省略することができます。
例えば、以下のように記述した場合でも、
HPFコンパイラ
が自動的に、実行時に利用可能な全抽象プロセッサ上に配列データを
マップするため、
上記のプログラムと全く同じように動作します。
INTEGER A(10),B(10),C(10)
DATA B /10*1/
DATA C /10*1/
!HPF$ DISTRIBUTE (BLOCK) :: A,B,C ! ONTO節の省略
DO I=1,10
A(I) = C(I)+B(I)
ENDDO
WRITE(*,*)A
END
1.2.2
例2
次は、以下のような行列積の計算をHPFによって並列化してみましょう。
INTEGER A(10,10),B(10,10),C(10,10)
DATA B /100*1/
DATA C /100*1/
DATA A /100*0/
DO I=1,10
DO J=1,10
DO K=1,10
A(J,I) = A(J,I)+B(J,K)*C(K,I)
ENDDO
ENDDO
ENDDO
WRITE(*,*)A
END
並列化の
粒度
をできるだけ大きくするために、最外側のDO Iのループで
並列化を行うことを考えます。並列化のためには、幾分かの
オーバヘッドが伴うので、出来るだけ大きな単位で並列化を
行った方が、並列化のためのオーバヘッドの総量を減らすことができるからです。
配列AとCは、添字中にIが出現する2次元目を
均等に分割すると良いでしょう。
配列Bは、Iの全ての繰り返しで、全ての要素が参照されるので、
各抽象プロセッサ上に、それぞれB全体のコピーを持たせることにしましょう。
HPFコンパイラは、
なにもマッピングを指定しない配列に対しては、
各抽象プロセッサ上に、配列全体の領域をそれぞれ割り付けますので、
Bに対するマッピングの指定は不要です。
できあがったHPFコードは以下のようになります。
INTEGER A(10,10),B(10,10),C(10,10)
DATA B /100*1/
DATA C /100*1/
DATA A /100*0/
!HPF$ DISTRIBUTE (*,BLOCK) :: A,C ! 2次元目を均等にマッピング
DO I=1,10
DO J=1,10
DO K=1,10
A(J,I) = A(J,I)+B(J,K)*C(K,I)
ENDDO
ENDDO
ENDDO
WRITE(*,*)A
END
このプログラムでは、全く通信を伴わずにIのループで処理の並列化が行われますが、
一方で配列Bは、その全体の大きさ分のメモリが、それぞれの抽象プロセッサ上に
とられてしまいますので、その分メモリを浪費することになります。
この場合、例えば以下のように、Bも2次元目でBLOCK分散すると、
各抽象プロセッサ上でBのために割り付けられる領域のサイズは、
抽象プロセッサ台数分の1に押さえられます。
INTEGER A(10,10),B(10,10),C(10,10)
DATA B /100*1/
DATA C /100*1/
DATA A /100*0/
!HPF$ DISTRIBUTE (*,BLOCK) :: A,B,C ! 2次元目を均等にマッピング
DO I=1,10
DO J=1,10
DO K=1,10
A(J,I) = A(J,I)+B(J,K)*C(K,I)
ENDDO
ENDDO
ENDDO
WRITE(*,*)A
END
しかし、Iのループを並列実行する際に、各抽象プロセッサが
他の抽象プロセッサ上にあるBの値を必要としますから、
例えば
HPF/ESの場合、
以下のような通信を含むコードが
生成され、その結果、実行性能はBを
マップしない場合に比べて低下することになります。
さらに、並列化されたループ中では、Bのリモートデータの値を
格納するための
一時領域
が必要となりますから (下の例のTMP_B)、
ループ実行中におけるメモリ使用量は、
Bをマップしない場合に比べてかえって増加してしまうことになります。
ALLOCATE( TMP_B(10,10) ) ! 一時領域の割り付け
call comm( TMP_B <- B ) ! 各プロセッサ上のBの値を一時領域にコピー
LB = MYID * 5
DO I= LB+1,LB+5
DO J=1,10
DO K=1,10
A(J,I) = A(J,I)+TMP_B(J,K)*C(K,I)
ENDDO
ENDDO
ENDDO
DEALLOCATE( TMP_B )
1.2.3
例3
次は、マッピングを指定しないために通信が発生する例を
見てみます。
以下の例では、配列A、B、Dは、BLOCK分散によりマップされていますが、
Cだけは、マッピングが指定されていないため、
全ての抽象プロセッサ上に、C全体が割り付けられることになります。
INTEGER A(10),B(10),C(10),D(10)
DATA B /10*1/
DATA D /10*1/
!HPF$ PROCESSORS P(2)
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: A,B,D
DO I=1,10
A(I) = B(I)
C(I) = D(I)
ENDDO
WRITE(*,*)A,C
END
例えば
HPF/ESの場合、
配列A、B、Dのマッピングに合わせて、
DO Iのループを
以下のように並列化しますが、Cが全抽象プロセッサ上に
複製されているため、
このままでは、P(1)上のC(6:10)の値、P(2)上のC(1:5)
の値が正しく設定されていません。
そのため、ループ実行後に、
各抽象プロセッサが計算したCの値を全抽象プロセッサで共有する
ために、通信の生成が必要となります。
! Processor P(1)
DO I = 1, 5
A(I) = B(I)
C(I) = D(I)
ENDDO
! Processor P(2)
DO I = 6, 10
A(I) = B(I)
C(I) = D(I)
ENDDO
この場合、
HPF/ESは、
以下のようにループ中で計算されるCの値を一旦一時領域
(以下の例ではTMP_C) に格納してから、ループ実行終了後に、
一時領域の値を各抽象プロセッサ上のCの値に反映させるような変形を行います。
LB = MYID * 5
ALLOCATE (TMP_C(LB+1:LB+5))
DO I = LB+1,LB+5
A(I) = B(I)
TMP_C(I) = D(I)
ENDDO
call comm(C <- TMP_C) ! 各抽象プロセッサ上のTMP_Cの値をCにコピー
DEALLOCATE (TMP_C)
これを、以下のように、全ての配列を
BLOCK分散でマップするように変更すると、
全く通信を伴わずにIのループが並列実行されるため、
Cをマップしない場合に比べてかなりの性能向上が見込めます。
また、一時領域も必要としないため、使用するメモリ量も削減されます。
INTEGER A(10),B(10),C(10),D(10)
DATA B /10*1/
DATA D /10*1/
!HPF$ PROCESSORS P(2)
!HPF$ DISTRIBUTE (BLOCK) ONTO P :: A,B,C,D
DO I=1,10
A(I) = B(I)
C(I) = D(I)
ENDDO
WRITE(*,*)A,C
END
このように、
プログラマがどのようなマッピングを選択するかは
、HPFコンパイラによる
計算マッピングの選択と通信の生成に大きな影響を与えるため、
結果として、プログラムの実行性能を大きく左右します。
一般的に、
各プロセッサで引用されるだけで、
定義されないデータは、マップしない方が良いし、
並列実行時に、定義されるデータは、適切な方法でマップした方が良い、
と言えるでしょう。
HPFの仕様は、HPF2.0仕様、HPF公認拡張仕様、
及び、JAHPFによる拡張仕様であるHPF/JA拡張仕様から構成されています。
これらを機能面で分類すると、大きく分けて、以下の3つにカテゴライズ
することができます。
- データマッピング関連の指示文
-
配列のプロセッサ構成上へのマッピング指定に関連する指示文です。
HPFの中心となる機能です。
- 計算マッピングと通信制御関連の指示文
-
現在のところ、HPFコンパイラは万能ではありません。
時には、並列化可能なループを、並列化可能であると
解析できなかったり、最適な計算マッピングが選択できなかったり、
リモートアクセスの必要がないのに、リモートアクセス用の
コードを生成してしまう場合もあります。
このような場合には、プログラマが、コンパイラに対して、
ループが並列化可能であることを教えたり (INDEPENDENT指示文) 、
最適な計算マッピングを指示したり (ON指示文) 、
リモートアクセスが発生しないことを教えたり (LOCAL節)
することにより、性能向上を図るための機能が用意されています。
- その他の機能
-
NUMBER_OF_PROCESSORS()に代表される組込み手続や、
マッピング問合せ、配列演算のためのライブラリ群、
及びHPFからHPF以外の手続を呼び出すための
外来手続の機能などが用意されています。
これら利用可能な仕様の一覧と、
仕様の定義元の分類を以下に示します。
各仕様の正確な定義に関しては、該当する仕様書を参照してください。
次の章では、HPFの各指示文の利用法に関して解説していきます。
データマッピング関連の指示文
|
仕様
|
目的
|
定義元
|
|
PROCESSORS指示文
|
プロセッサ構成の宣言
|
HPF2.0
|
|
TEMPLATE指示文
|
仮想配列の宣言
|
HPF2.0
|
|
DISTRIBUTE指示文/ALIGN指示文
|
マッピングの指定
|
HPF2.0
|
|
GEN_BLOCK分散/INDIRECT分散
|
新たな分散形式
|
HPF公認拡張
|
|
DYNAMIC指示文/REDISTRIBUTE指示文/REALIGN指示文
|
動的再マッピング
|
HPF公認拡張
|
|
INHERIT指示文
|
実引数のマッピングの仮引数への継承
|
HPF2.0
|
|
SEQUENCE指示文
|
HPFで記憶列結合、順序結合を利用するため
|
HPF2.0
|
|
SHADOW指示文
|
隣接計算のためのバッファ領域の宣言
|
HPF公認拡張
|
計算マッピングと通信制御関連の指示文
|
仕様
|
目的
|
定義元
|
|
INDEPENDENT指示文/NEW節/REDUCTION節
|
ループが並列化可能であることを指示
|
HPF2.0
|
|
種別指定付きREDUCTION節
|
任意の形式でのREDUCTION演算の記述
|
HPF/JA拡張
|
|
ON指示文
|
計算マッピングの指定
|
HPF公認拡張
|
|
LOCAL節
|
不要な通信の抑制
|
HPF/JA拡張
|
|
REFLECT指示文
|
シャドウ領域の通信制御
|
HPF/JA拡張
|
|
INDEX_REUSE指示文
|
通信やアドレス変換のオーバヘッド軽減
|
HPF/JA拡張
|
その他の機能
|
仕様
|
目的
|
定義元
|
|
組込み/ライブラリ手続
|
HPFで導入された組込み手続やライブラリ手続
|
HPF2.0/HPF公認拡張
|
|
外来手続
|
HPF以外の手続をHPF手続から引用する
|
HPF2.0/HPF公認拡張
|
|
HPF_LOCALライブラリ手続
|
HPF_LOCAL手続中で仮引数のマッピング情報を取得
|
HPF公認拡張
|